From Good To Great AI DevX
Up until this Memos project, my experience with AI coding assistants was what I’d call “AI pairing”—reaching for agent mode when I needed help exploring unfamiliar parts of a codebase. That was good, even magical at times. But I sensed there was more to fully agentic workflows, and I wanted to understand what separated good from great. Through building Memos, I’ve landed on some answers that work for me: great AI DevX comes from LLM independence, and independence requires high-quality Memory plus orchestration of planning context. Your mileage may vary—but this is a little bit about how I got there.
Your LLM is Always Onboarding
Let’s start with high-quality Memory.
There’s a core insight that is best expressed as this analogy: your LLM is always onboarding. Every session, you’re essentially handing context to a new team member who’s smart but has no memory of yesterday’s conversations.
This reframes a lot of what I like to call the “eat your veggies” engineering practices—good docs, clean architecture, clear commit messages, tests. We know we should do these things, but they often slip down the priority list. The reason they matter is that they help teammates understand complex, opaque systems when they come to them fresh.
When your LLM is always onboarding, that list of “teammates who need support” gets a lot longer—it’s every LLM session you spin up! High-quality, high-fidelity documentation is no longer something to backburner. It’s table stakes for agentic workflows.
This insight leads to two practical focus areas: learning loops that keep your Memory files accurate, and clean codebases that help the LLM plan effectively.
Learning Loops
Once I understood a bit more about Memory, I went looking for ways to make sessions do double duty—not just producing solutions, but capturing gaps in Memory files and updating them for future sessions. Over time, we should get less “dude, I told you to stop doing … " scenarios.
Code reviews are the primary mechanism. Review systems are a core process every dev team already knows, so why not leverage them? The inline comments on LLM-generated code are a powerful way to give the LLM feedback, so I gave Claude the ability to read them, and then prompt it to address them. At the end of the session, it will consider what should be updated in the Memory files. Done consistently, this feedback loop pushes toward agentic independence—eventually, the Memory files might get so good that most reviews are just that: reviews. (More details on this can be found in the post: Turn PR Comments Into LLM Feedback)
Most Memory file systems contain architecture docs, which drift from ground truth as the app evolves. I needed a mechanism to address this drift so I built an Update Architecture Command that finds which commit last touched the architecture doc, inspects all commits and PRs since then, and proposes updates. This is where good commit messages pay off—without them, this kind of loop becomes painfully manual.
These loops compound. The more corrections flow back into Memory, the fewer corrections you need to make.
Clean Codebases
Every time I’m in planning mode with Claude Code, the first thing it does is grep around the codebase for patterns (often via the built-in Explore subagent). It’s expanding context—layering on top of Memory to understand how the problem should be solved.
This means messy codebases directly degrade planning. Overwrought packages, multiple ways to do the same thing, bloated interfaces—all of this pollutes the LLM’s understanding. Worse, LLMs are notoriously bad at knowing when to not do something when their context is confusing. A human onboarding into a messy codebase will at least ask clarifying questions; the LLM often just confidently picks a bad pattern.
This struck home when I was struggling to get the voice CLI onto the Bubbletea TUI framework. The first pass was garbage and needed to be scrapped. It wasn’t until I pulled back and did it myself—learning Bubbletea properly, introducing clean separation between “widgets” and “containers”—that the LLM could add features without handholding. Good patterns in, good patterns out.
Planning
When we’ve built up high-quality Memory, we’ve created a foundation every LLM session can build on. But ground truth Memory alone isn’t enough for independent operation—the LLM also needs task-specific context before it starts generating. It needs a plan.
I find it useful to distinguish planning context from Memory proper: Memory is your static ground truth; planning context is ephemeral and scoped to a specific task. The most successful sessions have a planning phase where you and the LLM brainstorm the feature, then record the plan somewhere accessible. This plan becomes working memory that the current or future sessions execute against.
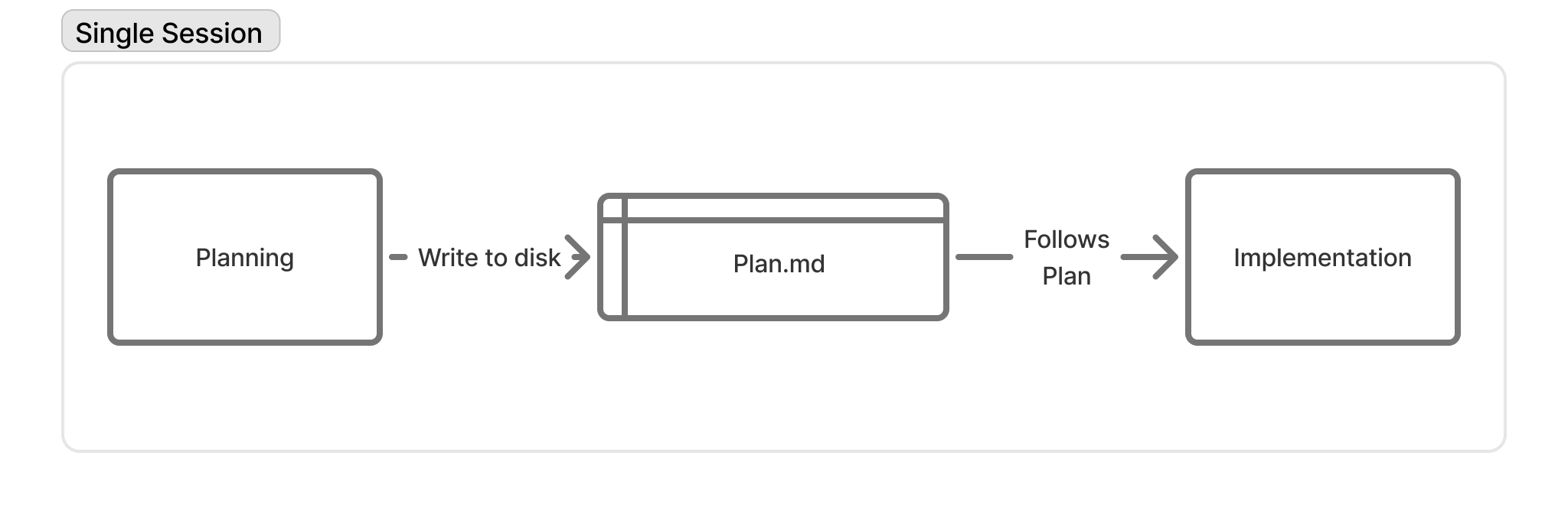
In the simplest case, planning and implementation happen in the same session. The plan gets written to disk as plan.md, and implementation follows.
But saving the plan to disk unlocks something: session independence. If you hit the context window limit before implementation starts, you can spin up a fresh session and just say “execute the plan.” The plan file carries the context forward.
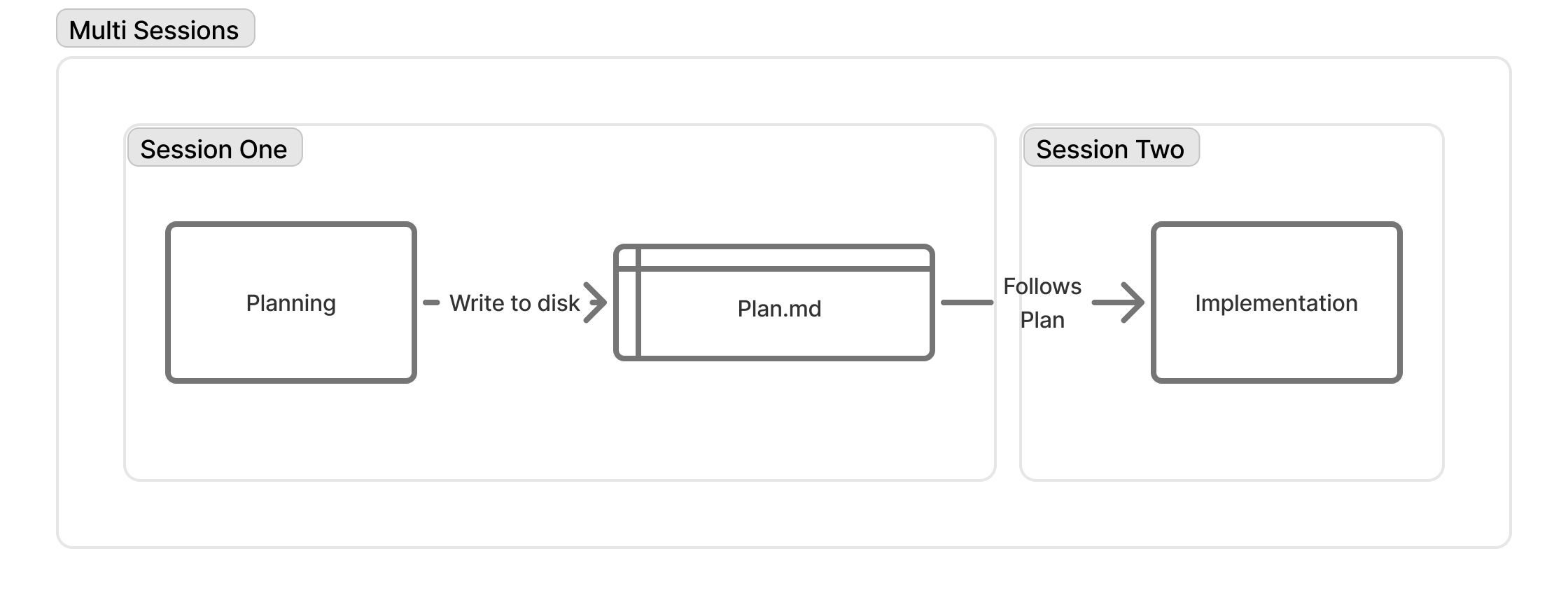
Now take one more leap. For complex features, the plan itself can be decomposed—a frontend_plan.md, a backend_plan.md, a testing_plan.md. Each becomes context for a separate implementation session, potentially running in parallel.
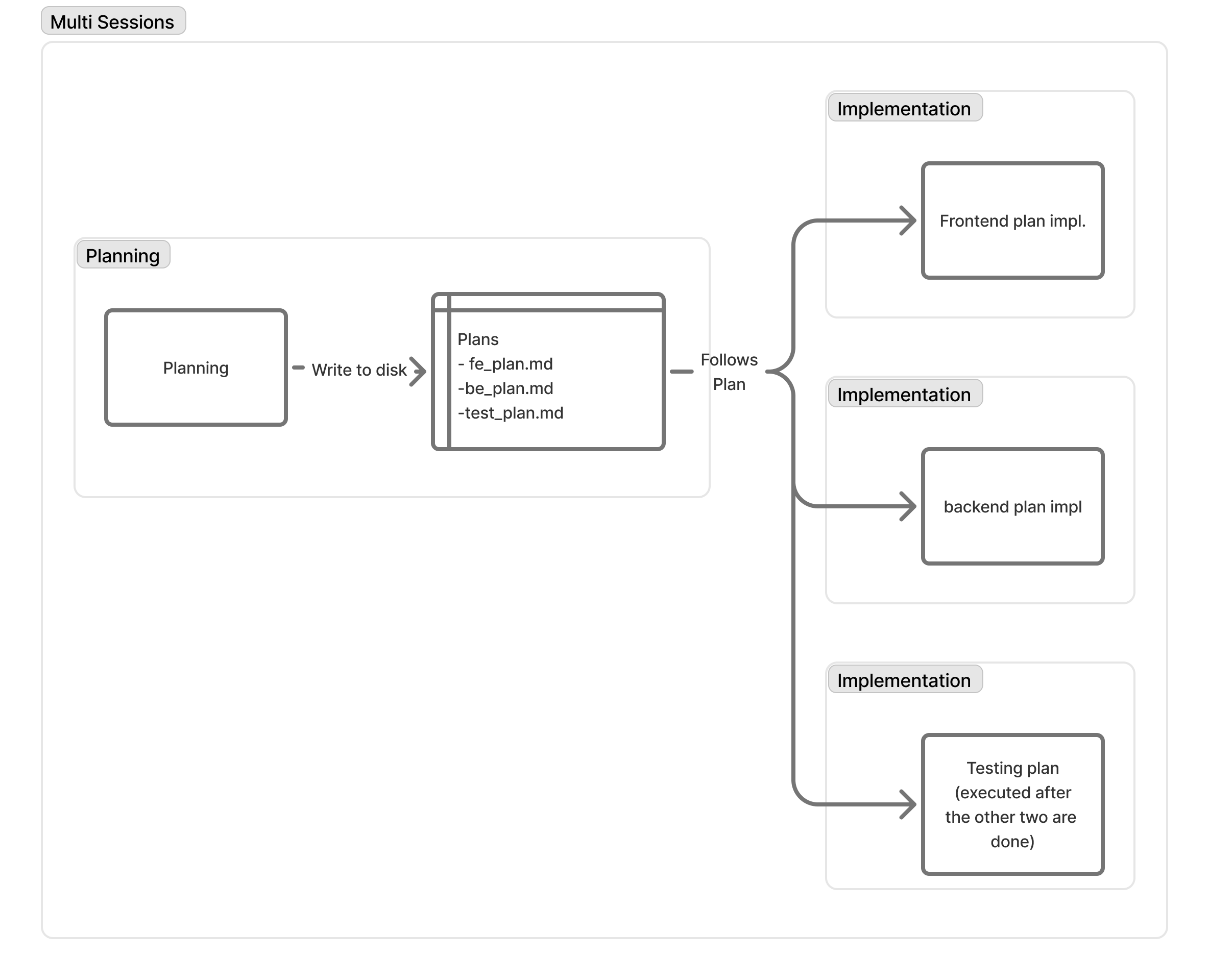
Sequencing may still matter—testing might need the other two to finish first—but the architecture allows for significant parallelism. One planning session fans out into many implementation sessions, each operating with focused context.
Parallelism Through Independence. As the third diagram shows, agentic independence creates the foundation for parallelism. By decoupling planning from implementation—and having a system to hand off planning context cleanly—we can scale execution horizontally without losing context quality.
Beyond Plan Files
Writing plan files to disk is the native, lightweight approach—and for many workflows, it’s enough. But as planning gets more complex, you may want more structure: dependencies between tasks, status tracking, the ability to query “what’s ready to work on?”
Plenty of apps exist to address this need, and through MCP, Claude Code and other tools can integrate with systems like Linear or Atlassian. There are also local-first tools like beads that keep planning data in your repo via SQLite.
I’ve started exploring this space but don’t have strong opinions yet. What I can say: the principle remains the same. These tools are just different ways to structure and deliver planning context to the LLM. It all comes back to context.
Final Thoughts
Before this project, most of my AI workflow was what I’d call “AI pairing”—the LLM helping me explore ideas and move faster. That was good. But great AI DevX, I’ve found, comes from LLM independence.
Independence requires two things: high-quality Memory (the ground truth that every session builds on), and planning context (the task-specific working memory that guides execution). Get these right, and you unlock not just better outputs, but the ability to scale—parallel sessions, each operating with focused context, each pushing toward the same goal.
Building Memos taught me this. I’m still learning, but the foundation feels solid now. Onward.
#AI Assisted Dev #Working in the Open #DevX #Claude Code #LLM #Workflows